Otimizando a Coleta de Dados do IBGE com o Pacote R 'orce'
Eduardo Leoni - SES/BA - IBGE
orce.RmdAbstract
Apresentamos o pacote Rorce, uma ferramenta criada
para otimizar a alocação de Unidades de Coleta em pesquisas do
IBGE, com o objetivo de minimizar os custos totais de coleta. Por
meio de um modelo de otimização baseado em programação linear
inteira mista, o pacote considera fatores como distâncias, tempo
de viagem, custos fixos das agências e necessidade de diárias para
encontrar a distribuição ideal das unidades de coleta. Estudos de
caso realizados com a Pesquisa Nacional de Saúde (PNS) no Espírito
Santo e a Pesquisa de Orçamentos Familiares (POF) na Bahia
demonstram o potencial do orce para alcançar reduções
significativas nos custos de coleta, chegando a até 40%. Além da
economia financeira, o pacote permite atingir um melhor
balanceamento da carga de trabalho entre as agências e oferece
flexibilidade para se adaptar às necessidades e restrições
específicas de cada pesquisa. O artigo explora estratégias
adicionais de otimização, como a reorganização da jurisdição das
agências e o ajuste do tempo de viagem considerado para o
pagamento de diárias. A análise dos resultados reforça a
importância da redução dos custos fixos como fator crucial para
alcançar maior eficiência e economia na coleta de dados. O
orce demonstra potencial para melhorar a eficiência
da coleta de dados do IBGE, viabilizando pesquisas de alta
qualidade com em um ambiente de restrição de gastos públicos.”
Introdução
A otimização dos custos de coleta de dados é um desafio comum em instituições de pesquisa que lidam com grandes volumes de informações distribuídas geograficamente. No caso do IBGE, a necessidade de otimizar a alocação de setores censitários, escolas, ou empresas, às agências de coleta do IBGE, se torna essencial, dada a complexidade logística e os elevados custos envolvidos no processo.
As pesquisas MUNIC (Pesquisa de Informações Básicas Municipais) e POF (Pesquisa de Orçamentos Familiares) são dois exemplos que ilustram a importância dessa otimização. A MUNIC, que coleta dados sobre a gestão e estrutura dos municípios brasileiros, e a POF, que investiga os hábitos de consumo das famílias brasileiras, envolvem a coleta de dados em milhares de domicílios e municípios, gerando altos custos logísticos.
O pacote orce é uma ferramenta projetada para otimizar a alocação de Unidades de Coleta (UCs), como setores censitários, prefeituras de municípios ou estabelecimentos de ensino, às agências do IBGE. A eficiência dessa alocação é fundamental para garantir a coleta de dados de forma econômica e eficaz em pesquisas e censos de grande escala, como o Censo Demográfico.
Coletar dados em milhares de domicílios espalhados por um vasto território é um grande desafio. O orce entra em ação para ajudar a definir a melhor estratégia, minimizando o tempo de deslocamento e os custos envolvidos.
Principais Características
-
Roteamento e Geocodificação:
- Para o caso em que as unidades de coleta são setores censitários, a
função
ponto_densidadeauxilia na identificação de locais representativos dentro dos setores censitários, priorizando áreas de alta densidade populacional para facilitar o acesso e garantir que o algorítimo de roteamento tenha destinos/origens válidos.
- Para o caso em que as unidades de coleta são setores censitários, a
função
-
Otimização Avançada da Alocação:
- O
orceimplementa um algoritmo inteligente que encontra a melhor forma de distribuir as UCs entre as agências do IBGE, levando em conta diversos fatores, como a distância entre os locais, o tempo de viagem, os custos fixos de cada agência e a necessidade de pagar diárias aos pesquisadores. - A função
alocar_ucspermite que você personalize as restrições, como a capacidade de cada agência e as preferências de localização, para que a alocação se adapte às necessidades específicas do seu projeto. A funçãoalocar_municipios, por sua vez, otimiza a alocação mantendo as unidades de coleta de um mesmo município com uma só agência.
- O
-
Cálculo de Custos Detalhados:
- O pacote considera as fronteiras administrativas para determinar quando é necessário pagar diárias aos pesquisadores, garantindo que os custos totais sejam calculados com precisão.
- Outros custos importantes, como combustível e tempo de viagem, também são levados em conta para fornecer uma estimativa completa dos gastos da coleta de dados.
-
Flexibilidade e Adaptabilidade:
- O
orcepermite que você personalize vários parâmetros, como o custo do combustível, o custo por hora de viagem, o consumo de combustível por quilômetro e as restrições específicas de cada agência. - Essa flexibilidade garante que o pacote possa ser adaptado a diferentes tipos de pesquisas e necessidades de coleta de dados, tornando-o uma ferramenta versátil para o IBGE.
- O
Impacto e Aplicações
O pacote orce tem o potencial de gerar um impacto
significativo na eficiência e na economicidade das operações de pesquisa
e censo do IBGE. Ao otimizar a alocação de UCs, o pacote pode:
- Reduzir custos de viagem e tempo de deslocamento: Ao minimizar as distâncias percorridas e o tempo gasto em viagens, o pacote contribui para a redução dos custos operacionais e aumenta a produtividade das equipes de coleta de dados.
- Otimizar a utilização dos recursos das agências: A alocação eficiente das UCs às agências garante que os recursos sejam utilizados de forma equilibrada. A opção de impor límites máximos e mínimos de unidades de coleta por agência ajuda a evitar sobrecarga em algumas agências e ociosidade em outras.
- Facilitar o planejamento e a gestão da coleta de dados: A capacidade de personalizar parâmetros e restrições permite que o pacote se adapte às necessidades específicas de cada projeto, facilitando o planejamento e a gestão das operações de coleta de dados.
Estudos de caso
Caso 1. Calculando os custos da coleta da MUNIC
A Pesquisa de Informações Básicas Municipais (MUNIC) realizada pelo Instituto Brasileiro de Geografia e Estatística (IBGE) é uma pesquisa fundamental para coletar informações essenciais sobre os municípios em todo o Brasil.
A alocação eficiente dos municípios às agências do IBGE responsáveis pela coleta de dados é um aspecto importante para o sucesso da pesquisa MUNIC, principalmente nas Unidades da Federação com maior número de agências e municípios. O processo envolve atribuir cada município à agência mais adequada, considerando fatores como proximidade geográfica, capacidade da agência e custos de viagem. A complexidade dessa tarefa aumenta com o número de municípios e agências envolvidas, tornando a alocação manual desafiadora e potencialmente levando a atribuições abaixo do ideal.
Para enfrentar esse desafio, o pacote orce utiliza
algoritmos avançados de otimização e incorpora vários fatores de custo
para identificar a estratégia de alocação mais eficiente, minimizando
despesas de viagem, carga de trabalho da equipe e custos gerais da
pesquisa.
Vamos começar a Superintendência Estadual do Espírito Santo, que tem 78 municípios, e 10 agências do IBGE.
map_uc_agencias(mnow%>%rename(uc_lat=municipio_sede_lat, uc_lon=municipio_sede_lon)) +
geom_point(aes(y=municipio_sede_lat, x=municipio_sede_lon, color=agencia_nome_bdo), data=mnow, alpha=3/4)+
geom_point(aes(y=agencia_lat, x=agencia_lon, color=agencia_nome_bdo), data=mnow, shape=2, size=3) +
labs(x="", y="", color="")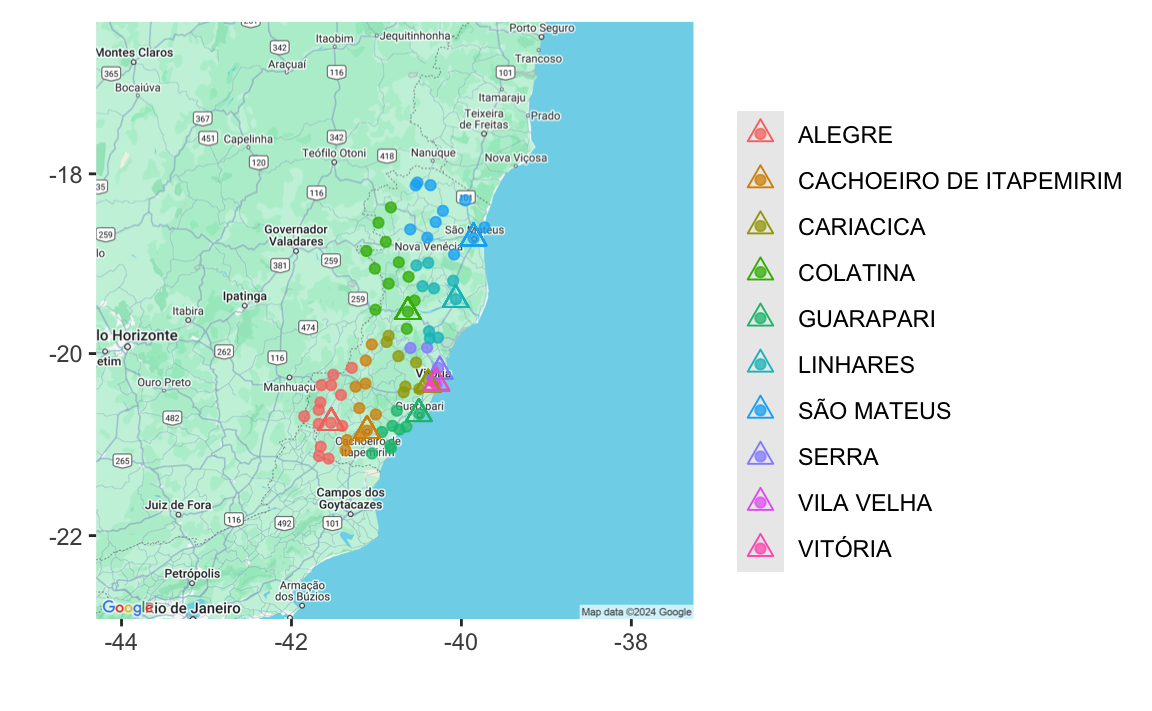
Vamos supor que seja necessário visitar todos os 78 municípios. Como podemos estimar o custo da coleta? Partiremos de algumas premissas.
- Municípios na mesma microrregião ou região metropolitana não pagam diária, a não ser que seja exigida pernoite.
- Quando o tempo de viagem é maior que 1,5 horas, paga-se diária, mesmo se na jurisdição da agência.
- A coleta presencial dura 2 dias.
- Quando há pernoite, são pagas 1,5 diárias, e a coleta é feita em 1 viagem(ns).
- Quando não há pernoite, são feitas 2 viagem(ns) (ida e volta). Há pagamento de meia-diária nos casos especificados no item 1.
- As viagens, feitas por veículos do IBGE, tem origem nas agências e destino nos municípios de coleta. Os veículos fazem 10 quilômetros por litro, e o custo do combustível é de 6 por litro. Importante: o consumo de combustível pode ser reduzido significativamente fazendo “roteiros”, em que uma viagem percorre mais de um município. Vamos ignorar, por enquanto, essa possibilidade.
- Diárias são calculadas para apenas um funcionário e tem o valor de 335.
ucs_now <- municipios_22%>%
sf::st_drop_geometry()%>%
filter(substr(municipio_codigo,1,2)==ufnow$uf_codigo)%>%
left_join(agencias_bdo_mun%>%select(agencia_codigo, municipio_codigo), by="municipio_codigo")%>%
mutate(uc=municipio_codigo)%>%
## com agências intramunicipais tem mais de uma agência associada a município
## vamos deixar só a primeira (em ordem numérica)
group_by(municipio_codigo)%>%
arrange(agencia_codigo)%>%
slice(1)%>%
mutate(viagens=params$viagens_munic, dias_coleta=params$dias_coleta_munic)Os dados com as unidades de coleta tem a seguinte estrutura:
gt1(ucs_now%>%
distinct(agencia_codigo, dias_coleta, viagens, .keep_all = TRUE)%>%
arrange(agencia_codigo, uc)%>%
head(10)%>%
ungroup%>%
select(uc=municipio_codigo, agencia_codigo, dias_coleta, viagens))| Uc | Agencia Codigo | Dias Coleta | Viagens |
|---|---|---|---|
| 3200201 | 320020100 | 2 | 1 |
| 3200508 | 320020100 | 2 | 1 |
| 3201100 | 320020100 | 2 | 1 |
| 3201159 | 320020100 | 2 | 1 |
| 3201803 | 320020100 | 2 | 1 |
| 3202009 | 320020100 | 2 | 1 |
| 3202306 | 320020100 | 2 | 1 |
| 3202454 | 320020100 | 2 | 1 |
| 3202553 | 320020100 | 2 | 1 |
| 3202652 | 320020100 | 2 | 1 |
Usamos como código da unidade de coleta (uc) o código
IBGE do município. Os dados devem ser únicos por uc. Dias
de coleta (dias_coleta) e número de viagens
(viagens) poderiam variar por município.
Precisamos também da distância de cada agência para cada município, e
se a viagem paga diária quando não há pernoite. No momento, estamos só
analisando os municípios com as respectivas agências de jurisdição, essa
diária não é devida. Mas ao analisar alocações alternativas, é
importante saber quando é que diárias são devidas. Essa informação está
na tabela agencias_municipios_diaria, disponível no pacote
para todas as unidades da federação.
agencias_municipios_diaria%>%
semi_join(ucs_now, by="municipio_codigo")%>%
distinct(agencia_codigo, diaria_municipio, .keep_all = TRUE)%>%
arrange(agencia_codigo)%>%
head(10)%>%gt1()| Agencia Codigo | Municipio Codigo | Diaria Municipio |
|---|---|---|
| 320020100 | 3200102 | TRUE |
| 320020100 | 3200201 | FALSE |
| 320120900 | 3200102 | FALSE |
| 320120900 | 3200136 | TRUE |
| 320130800 | 3200102 | TRUE |
| 320130800 | 3201308 | FALSE |
| 320150600 | 3200102 | TRUE |
| 320150600 | 3200136 | FALSE |
| 320240500 | 3200102 | TRUE |
| 320240500 | 3200300 | FALSE |
Precisamos também das distâncias, em quilômetros, entre cada agência
e cada sede municipal (disponível em
distancias_agencias_municipios_osrm), que combinamos com as
informações sobre as diárias
(agencias_municipios_diaria).
distancias_ucs <- distancias_agencias_municipios_osrm%>%
left_join(agencias_municipios_diaria_now,
by = join_by(agencia_codigo, municipio_codigo))%>%
mutate(uc=municipio_codigo)%>%
semi_join(ucs_now, by="uc")%>%
mutate(diaria_pernoite=duracao_horas>params$horas_viagem_pernoite)
gt1(distancias_ucs%>%
distinct(agencia_codigo, diaria_municipio, diaria_pernoite, .keep_all = TRUE)%>%
select(agencia_codigo, uc, distancia_km,
duracao_horas, diaria_municipio, diaria_pernoite)%>%
arrange(agencia_codigo, uc)%>%
head())| Agencia Codigo | Uc | Distancia Km | Duracao Horas | Diaria Municipio | Diaria Pernoite |
|---|---|---|---|---|---|
| 320020100 | 3200102 | 132,51 | 2,2 | TRUE | TRUE |
| 320020100 | 3200201 | 1,14 | 0,03 | FALSE | FALSE |
| 320020100 | 3200706 | 62,91 | 1,01 | TRUE | FALSE |
| 320020100 | 3201159 | 95,86 | 1,59 | FALSE | TRUE |
| 320120900 | 3200102 | 119,44 | 2,03 | FALSE | TRUE |
| 320120900 | 3200136 | 305,85 | 5,09 | TRUE | TRUE |
Observação: A coluna diaria_pernoite é calculada com
base na duração da viagem (ida). A partir de 1,5, são pagas diárias,
mesmo se na jurisdição da agência.
Estamos, agora, prontos para calcular os custos de coleta.
params_munic <- params[names(params)%in%params_alocar_ucs]
params_munic$remuneracao_entrevistador <- 0
params_munic$agencias <- agencias_now%>%mutate(dias_coleta_agencia_max=Inf)
params_munic$distancias_ucs <- distancias_ucs
params_munic$ucs <- ucs_now
params_munic$resultado_completo <- TRUE
params_munic$dias_coleta_entrevistador_max <- params$dias_coleta_entrevistador_max_munic
print(lapply(params_munic,head,2))
#> $custo_hora_viagem
#> [1] 10
#>
#> $custo_litro_combustivel
#> [1] 6
#>
#> $kml
#> [1] 10
#>
#> $valor_diaria
#> [1] 335
#>
#> $adicional_troca_jurisdicao
#> [1] 100
#>
#> $remuneracao_entrevistador
#> [1] 0
#>
#> $solver
#> [1] "cbc"
#>
#> $max_time
#> [1] 1800
#>
#> $rel_tol
#> [1] 0,01
#>
#> $agencias
#> Simple feature collection with 2 features and 9 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: -41,5317 ymin: -20,8496 xmax: -41,1114 ymax: -20,7613
#> Geodetic CRS: SIRGAS 2000
#> # A tibble: 2 × 10
#> uf_codigo agencia_codigo agencia_nome uorg agencia_lat agencia_lon
#> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 32 320020100 Alegre 593 -20.8 -41.5
#> 2 32 320120900 Cachoeiro de Itapemirim 594 -20.8 -41.1
#> # ℹ 4 more variables: geometry <POINT [°]>, custo_fixo <dbl>,
#> # max_uc_agencia <dbl>, dias_coleta_agencia_max <dbl>
#>
#> $distancias_ucs
#> agencia_codigo municipio_codigo distancia_km duracao_horas diaria_municipio
#> 1 320020100 3200102 132,51 2,20 TRUE
#> 2 320120900 3200102 119,44 2,03 FALSE
#> uc diaria_pernoite
#> 1 3200102 TRUE
#> 2 3200102 TRUE
#>
#> $ucs
#> # A tibble: 2 × 14
#> # Groups: municipio_codigo [2]
#> municipio_codigo municipio_sede_lon municipio_sede_lat municipio_nome
#> <chr> <dbl> <dbl> <chr>
#> 1 3200102 -41.1 -20.1 Afonso Cláudio
#> 2 3200136 -40.7 -19.0 Águia Branca
#> # ℹ 10 more variables: uf_codigo <chr>, uf_sigla <chr>, uf_nome <chr>,
#> # regiao_codigo <chr>, regiao_nome <chr>, municipio_populacao <int>,
#> # agencia_codigo <chr>, uc <chr>, viagens <int>, dias_coleta <int>
#>
#> $resultado_completo
#> [1] TRUE
#>
#> $dias_coleta_entrevistador_max
#> [1] 40
print(paste("parâmetros sem valor fixado: ", paste(setdiff(x=params_alocar_ucs, names(params_munic)), collapse=", ")))
#> [1] "parâmetros sem valor fixado: diarias_entrevistador_max, n_entrevistadores_min, dias_treinamento, agencias_treinadas, agencias_treinamento, distancias_agencias"
res <- do.call(what = alocar_ucs,
args=params_munic)Custos por agência
j <- res$resultado_ucs_jurisdicao%>%
left_join(agencias_now%>%sf::st_drop_geometry(), by="agencia_codigo")%>%
left_join(assistencias, by="agencia_codigo")%>%
group_by(assistencia_nome, agencia_nome)%>%
mutate(municipios=1)%>%
summarise(across(c(municipios, total_diarias, custo_diarias, distancia_total_km, custo_combustivel), sum))
#> `summarise()` has grouped output by 'assistencia_nome'. You can override using
#> the `.groups` argument.
gt(j%>%ungroup, groupname_col = 'assistencia_nome', rowname_col='agencia_nome')%>%
gt::summary_rows(fns = list(fn='sum', label="Total da Assistência"), fmt=~fmt_nums(.))%>%
fmt_nums()%>%
gt::cols_label_with(fn="nomear_colunas")%>%
gt::grand_summary_rows(fns = list(fn='sum', label="Total da Superintendência")
, fmt = ~fmt_nums(.))%>%
print_gt()| Municipios | Total Diarias | Custo Diarias | Distancia Total Km | Custo Combustivel | |
|---|---|---|---|---|---|
| Alegre | 14 | 1,5 | R$502 | 2.723 | R$1.634 |
| Cachoeiro de Itapemirim | 10 | 3 | R$1.005 | 1.892,12 | R$1.135 |
| Cariacica | 8 | 3 | R$1.005 | 1.347,08 | R$808 |
| Colatina | 12 | 7,5 | R$2.512 | 2.605,74 | R$1.563 |
| Guarapari | 9 | 1,5 | R$502 | 1.799,58 | R$1.080 |
| Linhares | 9 | 1,5 | R$502 | 1.796,6 | R$1.078 |
| Serra | 3 | 0 | R$0 | 414,28 | R$249 |
| São Mateus | 11 | 6 | R$2.010 | 2.259,2 | R$1.356 |
| Vila Velha | 1 | 0 | R$0 | 3,32 | R$2 |
| Vitória | 1 | 0 | R$0 | 21,08 | R$13 |
| Total da Superintendência | 78 | 24 | R$8.040 | 14.862 | R$8.917 |
resultado_ucs <- bind_rows(
res$resultado_ucs_otimo%>%mutate(plano= "otimo"),
res$resultado_ucs_jurisdicao%>%mutate(plano= "jurisdicao"))%>%
group_by(uc)%>%
mutate(mudanca=length(unique(agencia_codigo))>1)
toexport <- res$resultado_ucs_jurisdicao%>%
rename(municipio_codigo=uc)%>%
left_join(agencias_now%>%sf::st_drop_geometry(), by = join_by(agencia_codigo))%>%
left_join(municipios_22%>%select(municipio_codigo, municipio_nome), by = join_by(municipio_codigo))%>%
left_join(assistencias, by = join_by(agencia_codigo))%>%
transmute(
assistencia_nome,
agencia_codigo, agencia_nome,
municipio_nome, municipio_codigo,
distancia_km, duracao_horas, diaria, meia_diaria, trechos, total_diarias, custo_diarias, distancia_total_km, custo_combustivel, custo_horas_viagem, custo_deslocamento)
# export_dir <- file.path(here::here("vignettes", "articles", "munic"))
# dir.create(export_dir, recursive = TRUE, showWarnings = FALSE)
# export_path <- file.path(export_dir,paste0("munic_", ufnow$uf_codigo, "_", format(Sys.time(), "%Y%m%d_%H"), ".xlsx"))
# toexport_l <- lapply(toexport%>%split(.$assistencia_nome), function(x) janitor::remove_constant(x))
#sigba::excel(toexport_l, filename = export_path)Custos por município
mnow%>%
left_join(res$resultado_ucs_jurisdicao, by=c("municipio_codigo"="uc", "agencia_codigo"))%>%
transmute(municipio_nome, agencia_nome=capitalizar(agencia_nome), custo_diarias, custo_combustivel)%>%
sf::st_drop_geometry()%>%
arrange(desc(custo_diarias+custo_combustivel))%>%
head(10)%>%
gt1()| Municipio | Agencia | Custo Diarias | Custo Combustivel |
|---|---|---|---|
| Ecoporanga | Colatina | R$502 | R$218 |
| Água Doce do Norte | Colatina | R$502 | R$189 |
| Laranja da Terra | Cachoeiro de Itapemirim | R$502 | R$184 |
| Ponto Belo | São Mateus | R$502 | R$166 |
| Mucurici | São Mateus | R$502 | R$159 |
| Mantenópolis | Colatina | R$502 | R$153 |
| Barra de São Francisco | Colatina | R$502 | R$152 |
| Afonso Cláudio | Cachoeiro de Itapemirim | R$502 | R$143 |
| Itaguaçu | Cariacica | R$502 | R$143 |
| Montanha | São Mateus | R$502 | R$137 |
Lidando com contigências da coleta
Suponha agora que é necessário fazer uma visita ao município de Barra
de São Francisco, mas a agência de jurisdição não está disponível por
qualquer motivo (férias, licença de saúde, veículo do IBGE quebrado,
etc.) Quais são as agências alternativas para realizar essa coleta? A
função alocar_ucs retorna, opcionalmente, a lista completa
de combinações entre agências
municípios, que permite facilmente responder essa pergunta.
res$ucs_agencias_todas%>%
semi_join(munnow, by=c("uc"="municipio_codigo"))%>%
left_join(agencias_now, by="agencia_codigo")%>%
mutate(jurisdicao=agencia_codigo_jurisdicao==agencia_codigo)|>
transmute(agencia_nome=glue::glue("{agencia_nome} {if_else(jurisdicao, '(Jurisdição)', '')}"), duracao_horas, distancia_km, custo_diarias, custo_combustivel)%>%
arrange(custo_diarias+custo_combustivel)%>%
head(4)%>%
gt::gt()|>
print_gt()| Agencia | Duracao Horas | Distancia Km | Custo Diarias | Custo Combustivel |
|---|---|---|---|---|
| Colatina (Jurisdição) | 1,98 | 126,91 | R$502 | R$152 |
| São Mateus | 2,43 | 145,88 | R$502 | R$175 |
| Linhares | 2,77 | 168,86 | R$502 | R$203 |
| Serra | 3,72 | 236,99 | R$502 | R$284 |
Nota-se que outras agências podem realizar a coleta no municípios, e a qual custo.
Otimizando a alocação de municípios
A pergunta que segue, naturalmente, é, há algum município que teria custos de coleta menores se a coleta fosse realizada por agência diferente da de jurisdição? A resposta é sim!
res$ucs_agencias_todas%>%
group_by(municipio_codigo=uc)%>%
mutate(custo_diaria_combustivel=custo_diarias+custo_combustivel)%>%
arrange(custo_diaria_combustivel)%>%
slice(1)%>%
filter(agencia_codigo_jurisdicao!=agencia_codigo)|>
left_join(agencias_now, by="agencia_codigo")%>%
left_join(mnow%>%sf::st_drop_geometry()%>%
select(municipio_codigo,municipio_nome))%>%
ungroup%>%
transmute(municipio_nome, agencia_nome, distancia_km, duracao_horas, custo_diarias, custo_combustivel)%>%
arrange(custo_diarias+custo_combustivel)%>%
gt::gt()|>
print_gt()
#> Joining with `by = join_by(municipio_codigo)`| Municipio | Agencia | Distancia Km | Duracao Horas | Custo Diarias | Custo Combustivel |
|---|---|---|---|---|---|
| Governador Lindenberg | Colatina | 50,87 | 1,12 | R$0 | R$122 |
| Presidente Kennedy | Cachoeiro de Itapemirim | 38,27 | 0,71 | R$335 | R$92 |
| Itaguaçu | Colatina | 54,89 | 0,85 | R$335 | R$132 |
| Itarana | Colatina | 66,5 | 1,07 | R$335 | R$160 |
| São Gabriel da Palha | Colatina | 79,68 | 1,32 | R$335 | R$191 |
| Laranja da Terra | Colatina | 88,22 | 1,45 | R$335 | R$212 |
| Afonso Cláudio | Colatina | 111,28 | 1,73 | R$502 | R$134 |
| Ecoporanga | São Mateus | 146,89 | 2,62 | R$502 | R$176 |
Sabemos que os custos com combustível e diárias estão longe de ser os únicos fatores para selecionar a agência de coleta. A própria troca de agência de coleta tem um custo não desprezível. Os funcionários da agência de jurisdição provavelmente conhecem melhor o município de coleta, e até na gerência da coleta (que agência mesmo coleta o município X?) têm custos. Outras possibilidade é a distância em quilômetros ser menor, mas o tempo de viagem (por conta de qualidade da estrada, por exemplo) ser maior. O tempo gasto viajando certamente tem um custo para além das diárias e combustível.
Propomos avaliar o custo de deslocamento como a soma do custo de diárias, combustível, e custo adicional por hora de viagem correspondente a R$10. Além disso, só são propostas trocas que economizariam no mínimo R$100 no custo de deslocamento para o município.
mudancas <- resultado_ucs%>%
filter(mudanca)%>%
left_join(agencias_now%>%select(agencia_codigo,
agencia_nome,
agencia_lat,
agencia_lon), by="agencia_codigo")%>%
left_join(municipios_22%>%
sf::st_drop_geometry()%>%
select(uc=municipio_codigo, municipio_nome, municipio_sede_lat, municipio_sede_lon), by="uc")%>%
mutate(uc_lat=municipio_sede_lat, uc_lon=municipio_sede_lon)%>%
ungroup()
if (nrow(mudancas)>0) {
gt(
mudancas%>%
select(agencia_nome, municipio_nome, distancia_km, custo_deslocamento, plano)%>%
tidyr::pivot_wider(names_from = c("plano"), id_cols = c("municipio_nome"), values_from=c("agencia_nome", "distancia_km", "custo_deslocamento"))#%>%arrange(agencia_nome_otimo)
)%>%
gt::cols_label_with(fn="nomear_colunas")|>
print_gt()
}| Municipio | Agencia Otimo | Agencia Jurisdicao | Distancia Km Otimo | Distancia Km Jurisdicao | Custo Deslocamento Otimo | Custo Deslocamento Jurisdicao |
|---|---|---|---|---|---|---|
| Presidente Kennedy | Cachoeiro de Itapemirim | Guarapari | 38,27 | 113,37 | R$455 | R$676 |
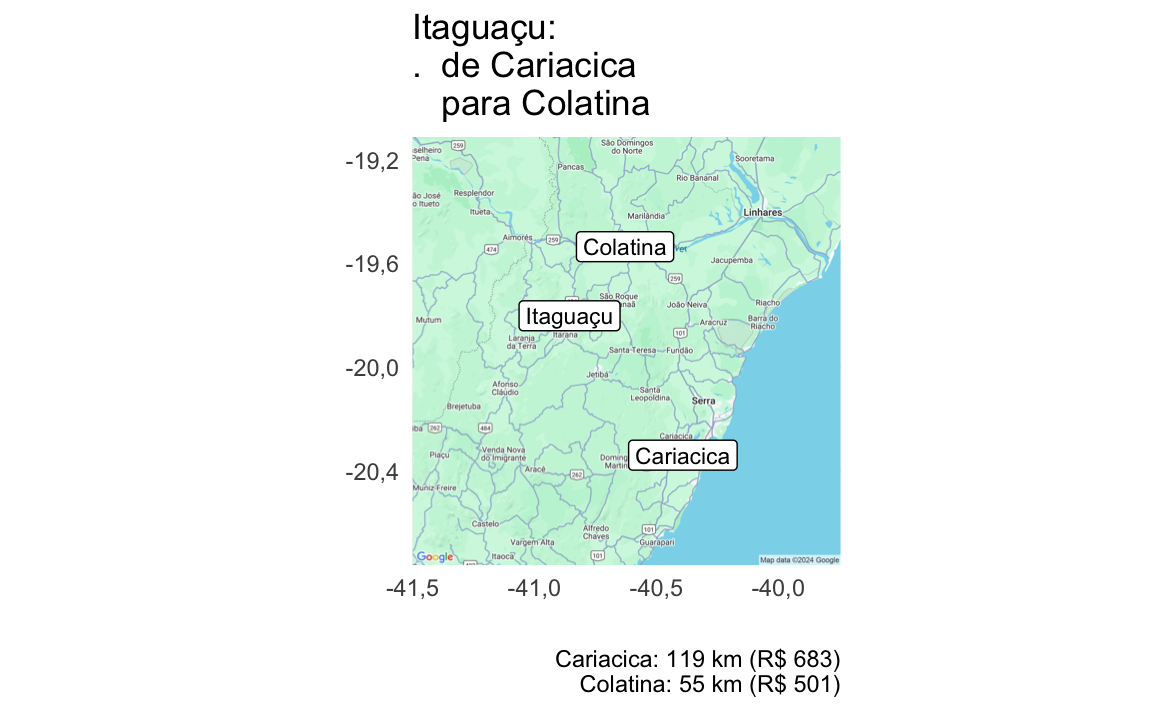
| Itaguaçu | Colatina | Cariacica | 54,89 | 119,31 | R$501 | R$683 |
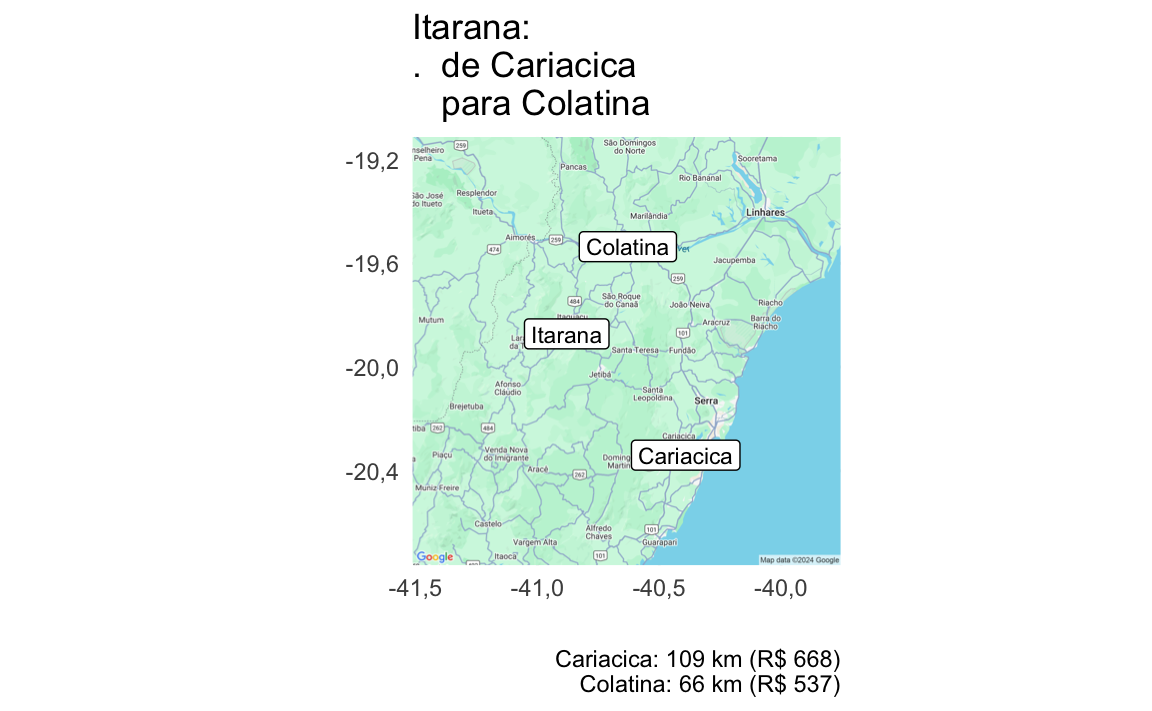
| Itarana | Colatina | Cariacica | 66,5 | 108,73 | R$537 | R$668 |
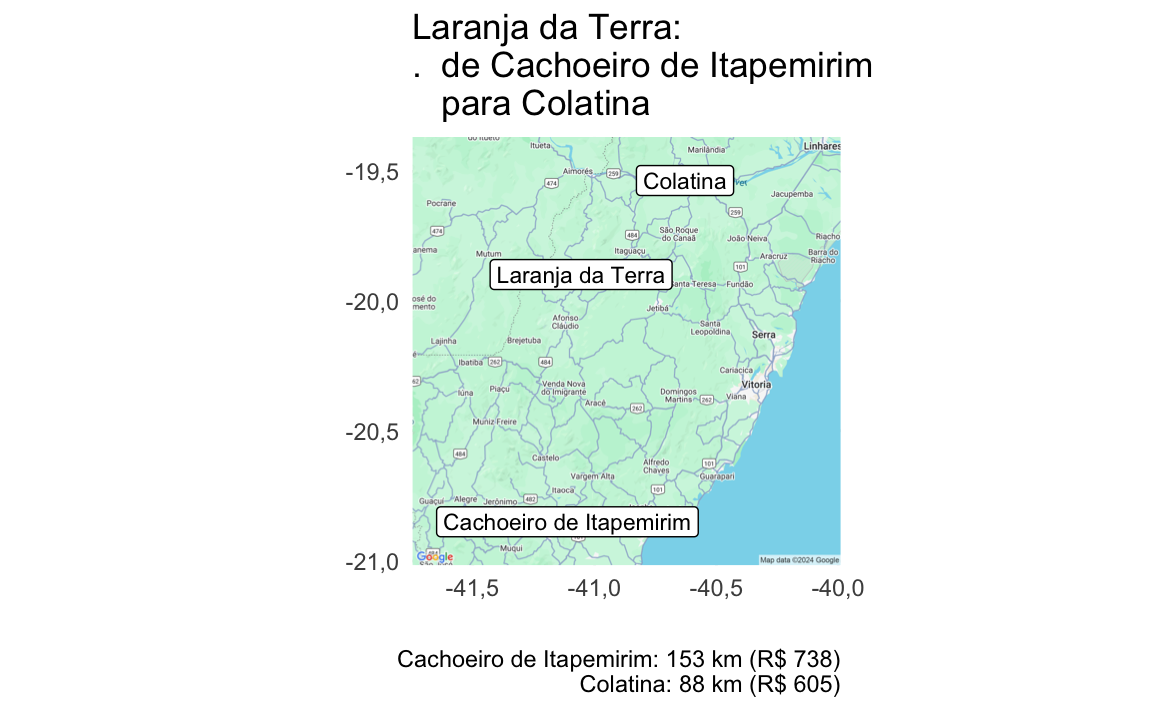
| Laranja da Terra | Colatina | Cachoeiro de Itapemirim | 88,22 | 153,06 | R$605 | R$738 |
if (nrow(mudancas)>0) {
mudancas_l <- mudancas%>%group_split(municipio_nome)
for (i in seq_along(mudancas_l)) {
dnow <- mudancas_l[[i]]%>%
arrange(plano)%>%
mutate(title=glue::glue("{municipio_nome}:\n. de {agencia_nome[1]}\n para {agencia_nome[2]}"),
subtitle=glue::glue("{agencia_nome}: {round(distancia_km)} km (R$ {round(custo_deslocamento)})"))
p <- map_uc_agencias(dnow) +
geom_label(aes(x=municipio_sede_lon, y=municipio_sede_lat, label=municipio_nome), data=dnow[1,], size=3) +
geom_label(aes(x=agencia_lon, y=agencia_lat, label=agencia_nome), data=dnow, size=3) +
theme_minimal() +
labs(title = dnow$title[1], caption = paste(dnow$subtitle, collapse='\n'), x="",y="")+
guides(color="none")
print(p)
}
}
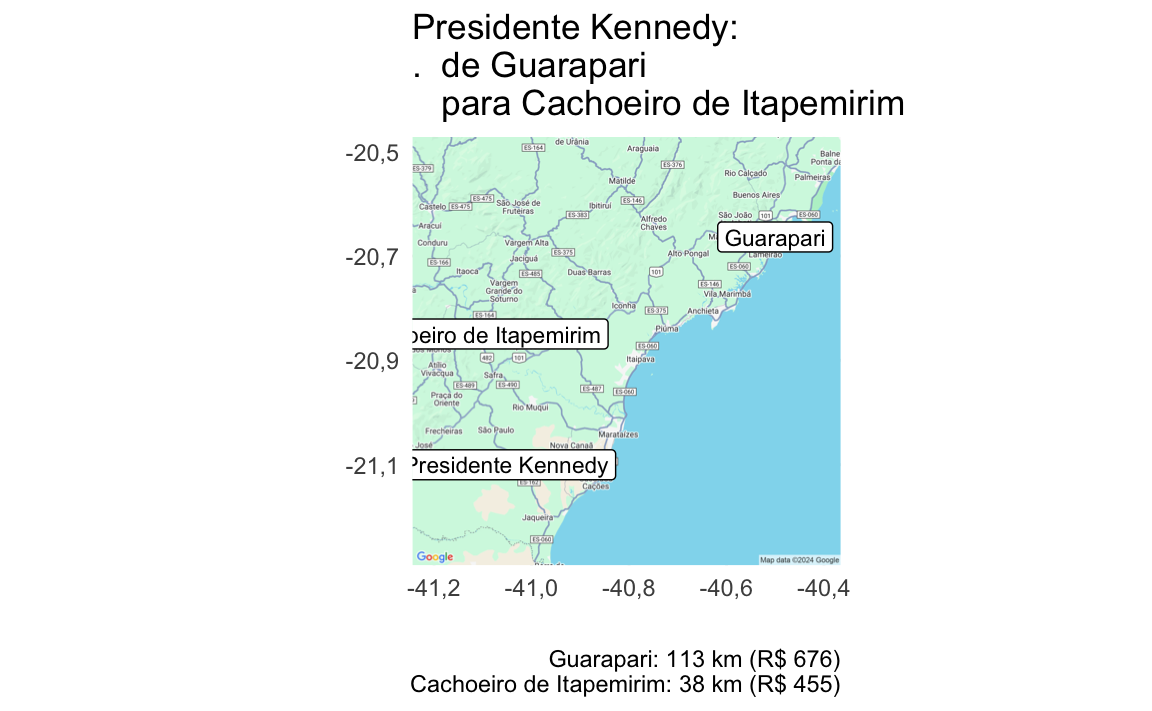
Resumo da otimização
resultado_ucs%>%
transmute(agencia_codigo, custo_diarias, custo_combustivel, custo_horas_viagem, total=custo_deslocamento, plano)%>%
group_by(plano)%>%
summarise(across(where(is.numeric), sum), n_agencias=n_distinct(agencia_codigo))%>%
tidyr::pivot_longer(cols=-plano)%>%
tidyr::pivot_wider(names_from=plano)%>%
mutate(reducao=jurisdicao-otimo,
reducao_pct=1-otimo/jurisdicao) -> resumo_planos| Name | Jurisdicao | Otimo | Reducao | Reducao Pct |
|---|---|---|---|---|
| custo_diarias | 8.040 | 7.370 | 670 | 8,3% |
| custo_combustivel | 8.917,2 | 8.918,75 | −1,55 | −0,0% |
| custo_horas_viagem | 2.531,6 | 2.532,8 | −1,2 | −0,0% |
| total | 19.488,8 | 18.821,55 | 667,25 | 3,4% |
| n_agencias | 10 | 10 | 0 | 0,0% |
economia_diarias <- resumo_planos%>%filter(name=="custo_diarias")%>%pull(reducao_pct)
economia_combustivel <- resumo_planos%>%filter(name=="custo_combustivel")%>%pull(reducao_pct)%>%round(2)
if (economia_combustivel > 0) {
economia_combustivel_str <- glue::glue("{round(economia_combustivel*100,1)}% a **menos**")
} else if (economia_combustivel<0) {
economia_combustivel_str <- glue::glue("apenas {-round(economia_combustivel*100,1)}% a mais")
} else {
economia_combustivel_str <- "o mesmo valor"
}Utilizando o plano otimizado, com 4 alterações de agência de coleta, é possível economizar 8% no valor das diárias, gastando o mesmo valor em combustível.
Resultados para outras Superintendências Estaduais1
filter_uf <- function(x) {
x%>%
filter(substr(agencia_codigo,1,2)==ufnow$uf_codigo,
!agencia_codigo%in%c("130420300","130140700"),
!municipio_codigo%in%c("1300300", "1301001", "1301407", "1301951", "1303106", "1304203"))
}
res_ufs <- vector(mode = "list", length = length(ufs_sem_missing_dist))
names(res_ufs) <- as.character(ufs_sem_missing_dist)
for (uf_codigo_now in ufs_sem_missing_dist) {
params_uf <- params_munic
ufnow <- ufs%>%filter(uf_codigo==uf_codigo_now)
distancias_ucs <- distancias_agencias_municipios_osrm%>%
left_join(agencias_municipios_diaria_now,
by = join_by(agencia_codigo, municipio_codigo))%>%
mutate(uc=municipio_codigo)%>%
filter_uf()
stopifnot(nrow(distancias_ucs%>%filter(is.na(distancia_km)))==0)
ucs_now <- distancias_ucs%>%
distinct(municipio_codigo)%>%
left_join(agencias_bdo_mun%>%select(agencia_codigo, municipio_codigo), by="municipio_codigo")%>%
mutate(uc=municipio_codigo)%>%
## com agências intramunicipais tem mais de uma agência associada a município
## vamos deixar só a primeira (em ordem numérica)
group_by(municipio_codigo)%>%
arrange(agencia_codigo)%>%
slice(1)%>%
mutate(viagens=params$viagens_munic, dias_coleta=params$dias_coleta_munic)%>%
filter_uf()
params_munic$agencias <- NULL
params_munic$distancias_ucs <- distancias_ucs%>%mutate(diaria_pernoite=duracao_horas>params$horas_viagem_pernoite)
params_munic$ucs <- ucs_now
params_munic$resultado_completo <- FALSE
res <- do.call(what = alocar_ucs,
args=params_munic)
resultado_ucs <- bind_rows(
res$resultado_ucs_otimo%>%mutate(plano= "otimo"),
res$resultado_ucs_jurisdicao%>%mutate(plano= "jurisdicao"))%>%
group_by(uc)%>%
mutate(mudanca=length(unique(agencia_codigo))>1)
resultado_ucs%>%
transmute(agencia_codigo, custo_diarias, custo_combustivel, custo_horas_viagem, total=custo_deslocamento, plano)%>%
group_by(plano)%>%
summarise(across(where(is.numeric), sum), n_agencias=n_distinct(agencia_codigo))%>%
tidyr::pivot_longer(cols=-plano)%>%
tidyr::pivot_wider(names_from=plano)%>%
mutate(reducao=jurisdicao-otimo,
reducao_pct=1-otimo/jurisdicao,uf_codigo=uf_codigo_now) -> resumo_planos
res_ufs[[as.character(uf_codigo_now)]] <- resumo_planos
}
res_ufs_df <- bind_rows(res_ufs)%>%filter(name=="total")%>%left_join(ufs, by="uf_codigo")
res_ufs_df%>%
ungroup%>%
select(regiao_nome, uf_nome, jurisdicao, otimo, reducao, reducao_pct)%>%
arrange(regiao_nome, desc(reducao))%>%
group_by(regiao_nome)%>%
gt()%>%
gt::summary_rows(fns=list(fn="sum", label="Total da Região"), columns = c("jurisdicao", "otimo", "reducao"), fmt = ~fmt_nums(.x, decimal_num = 0))%>%
gt::grand_summary_rows(fns=list(fn='sum', label="Total Brasil"), columns = c("jurisdicao", "otimo", "reducao"),fmt = ~fmt_nums(.x, decimal_num = 0))%>%
gt::cols_label(uf_nome="", jurisdicao="Jurisdição (R$)", otimo="Ótimo (R$)", reducao="Redução (R$)", reducao_pct="Redução (%)")%>%
print_gt(decimal_num=0, processar_nomes_colunas = FALSE)| Jurisdição (R$) | Ótimo (R$) | Redução (R$) | Redução (%) | ||
|---|---|---|---|---|---|
| Centro Oeste | |||||
| Goiás | 78.312 | 74.151 | 4.161 | 5,3% | |
| Mato Grosso | 69.773 | 67.477 | 2.297 | 3,3% | |
| Mato Grosso do Sul | 24.675 | 24.140 | 535 | 2,2% | |
| Total da Região | — | 172.761 | 165.768 | 6.993 | — |
| Nordeste | |||||
| Bahia | 97.099 | 91.748 | 5.352 | 5,5% | |
| Maranhão | 71.841 | 68.103 | 3.737 | 5,2% | |
| Piauí | 71.613 | 69.710 | 1.903 | 2,7% | |
| Rio Grande do Norte | 26.727 | 25.322 | 1.404 | 5,3% | |
| Ceará | 42.860 | 41.644 | 1.216 | 2,8% | |
| Paraíba | 38.651 | 38.178 | 473 | 1,2% | |
| Pernambuco | 27.336 | 27.009 | 327 | 1,2% | |
| Alagoas | 10.327 | 10.002 | 324 | 3,1% | |
| Sergipe | 9.363 | 9.231 | 132 | 1,4% | |
| Total da Região | — | 395.816 | 380.948 | 14.868 | — |
| Norte | |||||
| Tocantins | 58.107 | 57.074 | 1.033 | 1,8% | |
| Acre | 10.562 | 9.959 | 602 | 5,7% | |
| Rondônia | 23.711 | 23.314 | 397 | 1,7% | |
| Roraima | 9.806 | 9.806 | 0 | 0,0% | |
| Amapá | 11.193 | 11.193 | 0 | 0,0% | |
| Total da Região | — | 113.379 | 111.347 | 2.032 | — |
| Sudeste | |||||
| Minas Gerais | 182.764 | 178.514 | 4.251 | 2,3% | |
| São Paulo | 68.994 | 67.919 | 1.075 | 1,6% | |
| Espírito Santo | 19.489 | 18.822 | 667 | 3,4% | |
| Rio de Janeiro | 11.783 | 11.783 | 0 | 0,0% | |
| Total da Região | — | 283.030 | 277.037 | 5.993 | — |
| Sul | |||||
| Rio Grande do Sul | 98.559 | 92.542 | 6.018 | 6,1% | |
| Santa Catarina | 42.431 | 39.476 | 2.955 | 7,0% | |
| Paraná | 60.228 | 59.806 | 422 | 0,7% | |
| Total da Região | — | 201.218 | 191.824 | 9.394 | — |
| Total Brasil | — | 1.166.205 | 1.126.925 | 39.280 | — |
# ggplot(data = res_ufs_df%>%mutate(uf_nome=forcats::fct_reorder(uf_nome, reducao)), aes(x=reducao, y=uf_nome)) +
# geom_point() +
# scale_x_continuous(labels=scales::label_currency(prefix = "R$ ", decimal.mark = ",", big.mark = ".")) +
# labs(subtitle="Redução total nos custos de descolamento do plano ótimo\nem comparação com a manutenção das agência de jurisdição", x="", y="")Caso 2. Considerando os custos com entrevistadores: a coleta da POF 2024-25 na Superintendência Estadua da Bahia (SES/BA)
Vamos agora considerar a coleta da Pesquisa de Orçamentos Familiares (POF) na Bahia, planejada para ocorrer entre 2024 e 2025.
uf_codigo_now <- 29
ufnow <- ufs%>%filter(uf_codigo==uf_codigo_now)
## amostra_pof
load(file.path(pof2024ba:::package$cache_dir, "amostra_preliminar.rda"))
amostra_uf <- amostra_preliminar%>%
filter(substr(upa,1,2)==ufnow$uf_codigo)%>%
filter(!grepl("^2927408" ,agencia_codigo))%>%
distinct(upa, .keep_all = TRUE)%>%
rename(uc=upa)%>%
mutate(
dias_coleta = params$dias_coleta_pof,
viagens = params$viagens_pof)#%>%ungroup()%>%slice_sample(n=100)
## distancias upas
distancias_upas <- readRDS("/Users/eleon/gitlab/orce/data-raw/distancias_agencias_setores_osrm.rds")%>%
rename(uc=setor)%>%
mutate(municipio_codigo=substr(uc,1,7))%>%
left_join(agencias_municipios_diaria, by=c("agencia_codigo", "municipio_codigo"))%>%
semi_join(amostra_uf, by="uc")%>%
mutate(diaria_pernoite=duracao_horas>params$horas_viagem_pernoite)Parâmetros iniciais
## sem custo fixo nem custo de treinamento
params_pof_0 <- list(ucs=amostra_uf,
custo_litro_combustivel = params$custo_litro_combustivel,
custo_hora_viagem = params$custo_hora_viagem,
kml = params$kml,
valor_diaria = params$valor_diaria,
dias_treinamento = 0,
agencias_treinadas = NULL,
agencias_treinamento = NULL,
distancias_ucs=distancias_upas,
adicional_troca_jurisdicao = params$adicional_troca_jurisdicao,
remuneracao_entrevistador=0,
n_entrevistadores_min=2,
dias_coleta_entrevistador_max=params$dias_coleta_entrevistador_max_pof,
solver=params$solver,
max_time=params$max_time,
rel_tol=params$rel_tol
)
print(lapply(params_pof_0, head))
#> $ucs
#> # A tibble: 6 × 11
#> uc setor estrato_pof trimestre municipio_codigo municipio_nome
#> <chr> <chr> <dbl> <dbl> <chr> <chr>
#> 1 290570105000184 2905701… 2908 1 2905701 CAMACARI
#> 2 290650105000025 2906501… 2908 1 2906501 CANDEIAS
#> 3 290650105000106 2906501… 2908 1 2906501 CANDEIAS
#> 4 292100505000006 2921005… 2908 1 2921005 MATA DE SAO J…
#> 5 293320815000003 2933208… 2909 1 2933208 VERA CRUZ
#> 6 290080125000015 2900801… 2910 1 2900801 ALCOBACA
#> # ℹ 5 more variables: agencia_codigo <chr>, agencia_nome <chr>,
#> # situacao_tipo <chr>, dias_coleta <int>, viagens <int>
#>
#> $custo_litro_combustivel
#> [1] 6
#>
#> $custo_hora_viagem
#> [1] 10
#>
#> $kml
#> [1] 10
#>
#> $valor_diaria
#> [1] 335
#>
#> $dias_treinamento
#> [1] 0
#>
#> $agencias_treinadas
#> NULL
#>
#> $agencias_treinamento
#> NULL
#>
#> $distancias_ucs
#> uc agencia_codigo distancia_km duracao_horas agencia_lat
#> 1 290035505000027 290070200 263,82 4,01 -12,14108
#> 2 290035505000027 290320100 1007,91 13,63 -12,14613
#> 3 290035505000027 290390400 936,28 13,10 -13,25474
#> 4 290035505000027 290460500 682,01 9,84 -14,20330
#> 5 290035505000027 290490200 307,16 4,50 -12,60476
#> 6 290035505000027 290570100 348,16 4,82 -12,70437
#> agencia_lon ponto_origem setor_lat setor_lon municipio_codigo
#> 1 -38,42650 pontos_setores -10,67762 -38,01224 2900355
#> 2 -44,99788 pontos_setores -10,67762 -38,01224 2900355
#> 3 -43,40660 pontos_setores -10,67762 -38,01224 2900355
#> 4 -41,67101 pontos_setores -10,67762 -38,01224 2900355
#> 5 -38,96288 pontos_setores -10,67762 -38,01224 2900355
#> 6 -38,32298 pontos_setores -10,67762 -38,01224 2900355
#> diaria_municipio diaria_pernoite
#> 1 TRUE TRUE
#> 2 TRUE TRUE
#> 3 TRUE TRUE
#> 4 TRUE TRUE
#> 5 TRUE TRUE
#> 6 TRUE TRUE
#>
#> $adicional_troca_jurisdicao
#> [1] 100
#>
#> $remuneracao_entrevistador
#> [1] 0
#>
#> $n_entrevistadores_min
#> [1] 2
#>
#> $dias_coleta_entrevistador_max
#> [1] 200
#>
#> $solver
#> [1] "cbc"
#>
#> $max_time
#> [1] 1800
#>
#> $rel_tol
#> [1] 0,01
print(paste("parâmetros sem valor fixado: ", paste(setdiff(x=params_alocar_ucs, names(params_pof_0)), collapse=", ")))
#> [1] "parâmetros sem valor fixado: agencias, diarias_entrevistador_max, distancias_agencias, resultado_completo"Por conta de restrições no cronograma de coleta, que deve ser realizada em períodos específicos, a POF tem um mínimo de dois entrevistadores por agência. Em um ano de coleta, cada entrevistador poderá trabalhar 200 dias. Quando a coleta é feita com diária (pernoite), são necessárias 2 viagens. O total de dias de coleta por Unidade Primária de Amostragem (composta por um ou mais setores censitários) é 10. O deslocamento envolve, portanto, 10 idas e voltas para setores sem pernoite, ou 2 idas e voltas para os casos sem pernoite.
dagencias <- distancias_agencias_osrm
params_pof_1 <- modifyList(params_pof_0,
list(
distancias_agencias=distancias_agencias_osrm,
dias_treinamento = params$dias_treinamento_pof,# por funcionário
agencias_treinamento = c('292740800', '291080000')))
print(paste("parâmetros sem valor fixado: ", paste(setdiff(x=params_alocar_ucs, names(params_pof_1)), collapse=", ")))
#> [1] "parâmetros sem valor fixado: agencias, diarias_entrevistador_max, resultado_completo"
estrategias_pof <- bind_rows(
tibble(params_pof=list(params_pof_0),
descricao='Somente deslocamento'),
tibble(params_pof=list(params_pof_1), descricao="Custo de treinamento"),
# tibble(params_pof=list(modifyList(params_pof_1,
# list(
# ## diárias só com mais de duas horas de viagem
# distancias_ucs=distancias_upas%>%
# mutate(diaria_pernoite=duracao_horas>2)))),
# descricao="Custo de treinamento + redução diárias por pernoite"),
tibble(params_pof=list(modifyList(params_pof_1,
list(remuneracao_entrevistador=params$remuneracao_entrevistador*12))), descricao='Custo de treinamento + remuneração dos apms'),
# , tibble(params_pof=list(modifyList(params_pof_1,
# list(
# adicional_troca_jurisdicao=300))),
# descricao='custo de treinamento + Adicional troca de jurisdição R$300')
)%>%
mutate(resultado=purrr::map(params_pof, ~do.call(alocar_ucs, .x), .progress = TRUE))
estrategias_pof_sum <-
estrategias_pof%>%
rowwise(descricao)%>%
reframe(
bind_rows(
resultado$resultado_agencias_otimo%>%mutate(modelo="Ótimo"),
resultado$resultado_agencias_jurisdicao%>%mutate(modelo="Jurisdição"))%>%
group_by(modelo)%>%
mutate(n_agencias=1)%>%
summarise(
across(matches("custo|n_agencias"), ~sum(.x, na.rm=TRUE)),
))%>%
mutate(custo_total=custo_deslocamento+custo_fixo+custo_total_entrevistadores)%>%
select(descricao, modelo, n_agencias, custo_total, everything())Nesse caso básico, sem incluindo somente os custos de deslocamento, o resultado é o seguinte.
report_plans(estrategias_pof$resultado[[1]])%>%
gt::cols_hide(-matches(c("agencia_nome", "n_uc", "total_diarias", "combustivel", "custo_total", "custo_troca")))
#> Joining with `by = join_by(agencia_codigo)`| Custo Total Otimo | Custo Total Jurisdicao | Total Diarias Otimo | Total Diarias Jurisdicao | Custo Combustivel Otimo | Custo Combustivel Jurisdicao | |
|---|---|---|---|---|---|---|
| Barreiras | R$4.791 | R$10.110 | 0 | 19 | R$3.825 | R$2.940 |
| Brumado | R$8.058 | R$3.449 | 19 | 10 | R$1.289 | R$206 |
| Cruz das Almas | R$878 | R$1.488 | 0 | 0 | R$612 | R$1.080 |
| Eunápolis | R$1.046 | R$548 | 0 | 0 | R$748 | R$418 |
| Feira de Santana | R$3.914 | R$3.503 | 0 | 0 | R$3.002 | R$2.673 |
| Ibotirama | R$11.260 | R$11.628 | 28 | 28 | R$1.319 | R$1.615 |
| Ilhéus | R$4.868 | R$8.981 | 10 | 10 | R$1.310 | R$4.526 |
| Ipiaú | R$13.335 | R$7.530 | 15 | 10 | R$6.466 | R$3.329 |
| Itabuna | R$9.707 | R$8.259 | 19 | 19 | R$2.596 | R$1.471 |
| Itamaraju | R$4.461 | R$5.900 | 10 | 10 | R$963 | R$2.138 |
| Itapetinga | R$6.643 | R$5.012 | 0 | 0 | R$5.215 | R$3.930 |
| Jaguaquara | R$4.792 | R$2.433 | 5 | 0 | R$2.305 | R$1.843 |
| Porto Seguro | R$3.757 | R$4.693 | 10 | 10 | R$411 | R$1.085 |
| Santa Rita de Cássia | R$7.158 | R$14.158 | 19 | 38 | R$617 | R$1.120 |
| Santo Amaro | R$3.898 | R$4.445 | 0 | 0 | R$3.012 | R$3.453 |
| Santo Antônio de Jesus | R$4.483 | R$4.322 | 0 | 0 | R$3.445 | R$3.322 |
| Seabra | R$7.733 | R$4.162 | 19 | 10 | R$1.038 | R$743 |
| Teixeira de Freitas | R$4.871 | R$4.352 | 0 | 0 | R$3.769 | R$3.360 |
| Valença | R$6.353 | R$16.738 | 0 | 28 | R$4.971 | R$5.602 |
| Vitória da Conquista | R$14.260 | R$25.835 | 28 | 57 | R$3.639 | R$5.250 |
| Xique Xique | R$5.793 | R$2.183 | 10 | 0 | R$2.024 | R$1.699 |
| Agências sem alteração* | R$85.079 | R$85.079 | 76 | 76 | R$46.124 | R$46.124 |
| Total Superintendência | R$217.140 | R$234.808 | 267 | 323 | R$98.699 | R$97.927 |
| ** Agências sem alteração: Alagoinhas, Bom Jesus da Lapa, Cachoeira, Camaçari, Cipó, Conceição do Coité, Esplanada, Euclides da Cunha, Guanambi, Ipirá, Irecê, Itaberaba, Jacobina, Jequié, Jeremoabo, Juazeiro, Livramento de nossa Senhora, Morro do Chapéu, Paulo Afonso, Poções, Remanso, Riachão do Jacuípe, Ribeira do Pombal, Santa Maria da Vitória, São Francisco do Conde, Senhor do Bonfim, Serrinha | ||||||
vs <- c("n_agencias", "custo_total", 'custo_total_entrevistadores', 'custo_diarias', 'custo_combustivel')
pct <- function(x) (x[2]/x[1])-1
estrategias_pof_sum%>%
group_by(descricao)%>%
#arrange(modelo)%>%
select(-modelo)%>%
summarise(across(everything(), diff, .names = "{.col}_dif"),
across(-ends_with("_dif"), pct, .names = "{.col}_pct")
)%>%
select(descricao, starts_with(vs))%>%
arrange(desc(n_agencias_dif))%>%
gt::gt() -> sumario_pof_0
sumario_pof <- sumario_pof_0
for (i in c("n_agencias", "custo_total", 'custo_total_entrevistadores', 'custo_diarias', 'custo_combustivel')) {
sumario_pof <- sumario_pof%>%
fmt_percent(matches("_pct"), decimals = 0)%>%
gt::cols_merge_n_pct(col_pct = paste0(i,"_pct"), col_n = paste0(i, "_dif"))
}
sumario_pof%>%
fmt_currency(matches("_dif"), decimals = 0)%>%
fmt_number(matches("n_agencias_dif"), decimals = 0)%>%
gt::cols_label(descricao='Modelo')%>%
gt::cols_label_with(fn = ~ gsub("_dif", "", .x))%>%
gt::tab_caption("Redução de custos promovido pela otimização da rede de coleta")%>%
print_gt()| Modelo | N Agencias | Custo Total | Custo Total Entrevistadores | Custo Diarias | Custo Combustivel |
|---|---|---|---|---|---|
| Somente deslocamento | 0 | −R$17.668 (−7,5%) | R$0 | −R$18.760 (−17,3%) | R$772 (0,8%) |
| Custo de treinamento | −15 (−31,2%) | −R$55.289 (−12,4%) | −R$66.473 (−31,4%) | −R$4.355 (−4,0%) | R$12.249 (12,5%) |
| Custo de treinamento + remuneração dos apms | −41 (−85,4%) | −R$2.351.092 (−66,6%) | −R$2.817.185 (−85,5%) | R$409.872 (378,8%) | R$46.520 (47,5%) |
A tabela demonstra o impacto da otimização da rede de coleta em diferentes cenários, considerando custos fixos, diárias, combustível e número de agências envolvidas2.
Principais Observações:
Em todos os cenários, a otimização resultou em redução significativa do custo total.
Realocação de UPAs entre as agências: A redistribuição ótima de UPAs entre as agências, sem alteração no número de agências na coleta, tem o não desprezível impacto de R$ 19 mil.
Custo de treinamento: Se incluímos os custos de treinamento (2 funcionários por agência) o número de agência ótimo diminui bastante (cerca de 30%), e o valor economizado salta para cerca de R$ 55 mil. O custo de deslocamento (total de combustível e diárias) aumenta após a otimização. Isso é explicado pela necessidade de percorrer distâncias maiores para cobrir as UCs com uma rede menor de agências. No entanto, esse aumento é mais do que compensado pela redução dos custos com treinamento, resultando em uma economia geral.
Custos com remuneração dos entrevistadores: Quando incluímos a despesa com e remuneração dos entrevistadores, além do custo de treinamento dos mesmos, a economia gerada passa de R$ 1 milhão. É definitivamente aqui que está o mais efetivo instrumento para reduzir os custos de coleta.
Caso 3. PNADC e CNEFE
A seção anterior demonstrou que, pelo menos no caso da coleta da POF da Bahia, é possível atingir uma significativa redução de custos de coleta, quando contabilizamos a remuneração dos entrevistadores.
## amostra mestra/pnadc
#pontos_upas_29 <- readRDS(here::here("data-raw/pontos_upas_29.rds"))
uf_codigo_now <- 29
ufnow <- ufs%>%filter(uf_codigo==uf_codigo_now)
amostra_mestra <- readr::read_rds(here::here("data-raw/amostra_br_2024_01_2025_06.rds"))%>%
filter(ano_mes>=as.Date("2024-07-01"), ano_mes<=as.Date("2025-06-01"), uf_codigo==uf_codigo_now)
amostra_pnadc <- amostra_mestra%>%
distinct(uc=upa, pesquisa=paste("pnadc", substr(ano_mes,1,7)), agencia_codigo, dias_coleta=params$dias_coleta_pnadc, viagens=params$viagens_pnadc)
library(lubridate)## so months works
#>
#> Attaching package: 'lubridate'
#> The following objects are masked from 'package:base':
#>
#> date, intersect, setdiff, union
amostra_cnefe <- amostra_mestra%>%
filter(entrevista_numero==1)%>%
mutate(ano_mes=ano_mes-months(3))%>%
distinct(uc=upa, pesquisa=paste("cnefe", substr(ano_mes,1,7)), agencia_codigo, dias_coleta=params$dias_coleta_cnefe, viagens=params$viagens_cnefe)
carga_pnadc <- bind_rows(amostra_cnefe, amostra_pnadc)%>%
group_by(uc, agencia_codigo, municipio_codigo=substr(uc,1,7))%>%
summarise(dias_coleta=sum(dias_coleta), viagens=sum(viagens))
#> `summarise()` has grouped output by 'uc', 'agencia_codigo'. You can override
#> using the `.groups` argument.
carga_pnadc_uf <- carga_pnadc%>%
filter(substr(uc,1,2)==ufnow$uf_codigo)%>%
## Importante: Sem as agências de Salvador
filter(!grepl("2927408", agencia_codigo))%>%
#ungroup#%>%filter(agencia_codigo%in%c("291360600", "291480200", "292870300", "293290300", "290490200", "292740800", "292740801", "291640100"))
ungroup#%>%filter(agencia_codigo%in%unique(agencia_codigo)[1:20])
## distancias uc
fname <- here::here(paste0("data-raw/distancias_agencias_upas_osrm_", uf_codigo_now, ".rds"))
distancias_ucs_all <- readRDS(fname)%>%
rename(uc=upa)%>%
transmute(uc, agencia_codigo, distancia_km, duracao_horas, municipio_codigo=substr(uc,1,7), ponto_origem)%>%
left_join(agencias_municipios_diaria, by=c("agencia_codigo", "municipio_codigo"))%>%
semi_join(carga_pnadc_uf, by="uc")%>%
mutate(diaria_pernoite=duracao_horas>params$horas_viagem_pernoite)%>%
group_by(uc, agencia_codigo)%>%
## só a configuração de upa mais distante
arrange(desc(duracao_horas))%>%
slice(1)%>%
ungroup()
distancias_ucs_all%>%ungroup%>%count(ponto_origem)
#> # A tibble: 1 × 2
#> ponto_origem n
#> <chr> <int>
#> 1 pontos_upas 36000
agencias_uf <- carga_pnadc_uf%>%
group_by(agencia_codigo)%>%
summarise(n_ucs_jurisdicao=n(), dias_coleta_jurisdicao=sum(dias_coleta))%>%
mutate(dias_coleta_agencia_max=Inf,
custo_fixo=0)%>%
## tira Cipó
mutate(dias_coleta_agencia_max=if_else(agencia_codigo=="290790500", 0, dias_coleta_agencia_max))
## sem custo fixo nem custo de treinamento
params_pnadc_0 <- list(ucs=carga_pnadc_uf,
agencias=agencias_uf,
custo_litro_combustivel = params$custo_litro_combustivel,
custo_hora_viagem = params$custo_hora_viagem,
kml = params$kml,
valor_diaria = params$valor_diaria,
## em um ano de coleta, um entrevistador consegue
## 48 upas pnadc / 24 upas POF / 18 Municipios
dias_coleta_entrevistador_max=params$dias_coleta_entrevistador_max_pnadc,
diarias_entrevistador_max=Inf,
dias_treinamento = 0,
agencias_treinadas = NULL,
agencias_treinamento = NULL,
distancias_ucs=distancias_ucs_all,
## for symphony solver
#gap_limit=5,
adicional_troca_jurisdicao = params$adicional_troca_jurisdicao,
solver=params$solver,
max_time=params$max_time,
rel_tol=params$rel_tol,
resultado_completo=FALSE
)
library(tictoc)
tic()
estrategias_pnadc <- bind_rows(
tibble(params_pnadc=list(params_pnadc_0),
descricao='sem custo fixo / sem custo de treinamento'),
tibble(params_pnadc=list(modifyList(params_pnadc_0,
list( remuneracao_entrevistador=params$remuneracao_entrevistador*12)
)),
descricao=glue::glue('sem mínimo de entrevistador, remuneracao entrevistador por mês {params$remuneracao_entrevistador}, sem custo fixo')),
tibble(params_pnadc=list(modifyList(params_pnadc_0,
list(n_entrevistadores_min=2, remuneracao_entrevistador=params$remuneracao_entrevistador*12)
)),
descricao=glue::glue('mínimo de entrevistador=2, remuneracao entrevistador por mês {params$remuneracao_entrevistador}, sem custo fixo')),
tibble(params_pnadc=list(modifyList(params_pnadc_0,
list(n_entrevistadores_min=3, remuneracao_entrevistador=params$remuneracao_entrevistador*12)
)),
descricao=glue::glue('mínimo de entrevistador=3, remuneracao entrevistador {params$remuneracao_entrevistador} por mês, sem custo fixo'))
)%>%
ungroup%>%#slice(1:2)%>%
mutate(resultado=purrr::map(params_pnadc, ~do.call(alocar_ucs, .x)))
toc()
#> 0,03 sec elapsed
estrategias_pnadc_sum <-
estrategias_pnadc%>%
rowwise(descricao)%>%
reframe(
bind_rows(
resultado$resultado_agencias_otimo%>%mutate(modelo="Ótimo"),
resultado$resultado_agencias_jurisdicao%>%mutate(modelo="Jurisdição"))%>%
group_by(modelo)%>%
mutate(n_agencias=1)%>%
summarise(across(matches("custo|n_agencias"), ~sum(.x, na.rm=TRUE))))%>%
mutate(custo_total=custo_deslocamento+custo_fixo+custo_total_entrevistadores)%>%
select(descricao, modelo, n_agencias, custo_total, everything())
report_plans(estrategias_pnadc$resultado[[4]])
#> Joining with `by = join_by(agencia_codigo)`| Perde | Recebe | Custo Total Otimo | Custo Total Jurisdicao | Total Diarias Otimo | Total Diarias Jurisdicao | Custo Combustivel Otimo | Custo Combustivel Jurisdicao | Entrevistadores Otimo | Entrevistadores Jurisdicao | N Agencias Otimo | N Agencias Jurisdicao | N Otimo | N Jurisdicao | Dias Coleta Otimo | Dias Coleta Jurisdicao | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alagoinhas | 3 | 7 | R$136.347 | R$130.766 | 0 | 34 | R$31.958 | R$18.055 | 3 | 3 | 1 | 1 | 29 | 25 | 595 | 520 |
| Barreiras | 6 | 7 | R$193.285 | R$205.888 | 168 | 224 | R$32.267 | R$27.219 | 3 | 3 | 1 | 1 | 27 | 26 | 550 | 525 |
| Camaçari | 0 | 9 | R$198.845 | R$157.369 | 0 | 0 | R$29.611 | R$22.335 | 5 | 4 | 1 | 1 | 44 | 35 | 925 | 740 |
| Conceição do Coité | 1 | 18 | R$177.510 | R$126.734 | 0 | 24 | R$37.709 | R$17.102 | 4 | 3 | 1 | 1 | 33 | 16 | 725 | 360 |
| Cruz das Almas | 2 | 12 | R$119.820 | R$113.735 | 0 | 0 | R$17.417 | R$13.015 | 3 | 3 | 1 | 1 | 27 | 17 | 585 | 355 |
| Eunápolis | 0 | 22 | R$243.403 | R$107.496 | 356 | 24 | R$21.462 | R$2.173 | 3 | 3 | 1 | 1 | 29 | 7 | 570 | 145 |
| Feira de Santana | 4 | 3 | R$152.693 | R$181.715 | 0 | 0 | R$18.624 | R$16.299 | 4 | 5 | 1 | 1 | 38 | 39 | 795 | 820 |
| Guanambi | 0 | 7 | R$241.176 | R$178.422 | 357 | 190 | R$19.210 | R$13.888 | 3 | 3 | 1 | 1 | 27 | 20 | 600 | 430 |
| Ibotirama | 3 | 16 | R$258.187 | R$151.882 | 396 | 127 | R$22.768 | R$10.221 | 3 | 3 | 1 | 1 | 25 | 12 | 580 | 280 |
| Ipiaú | 2 | 8 | R$163.845 | R$142.910 | 60 | 49 | R$36.845 | R$23.151 | 3 | 3 | 1 | 1 | 27 | 21 | 600 | 480 |
| Ipirá | 3 | 13 | R$180.433 | R$131.238 | 146 | 74 | R$27.359 | R$7.879 | 3 | 3 | 1 | 1 | 20 | 10 | 450 | 245 |
| Itabuna | 4 | 15 | R$151.032 | R$152.716 | 68 | 127 | R$24.766 | R$10.743 | 3 | 3 | 1 | 1 | 28 | 17 | 580 | 365 |
| Jacobina | 0 | 14 | R$217.105 | R$125.369 | 263 | 29 | R$25.255 | R$14.975 | 3 | 3 | 1 | 1 | 27 | 13 | 550 | 260 |
| Jaguaquara | 0 | 9 | R$171.230 | R$133.912 | 103 | 44 | R$31.488 | R$17.777 | 3 | 3 | 1 | 1 | 28 | 19 | 580 | 390 |
| Juazeiro | 2 | 11 | R$254.967 | R$172.331 | 382 | 181 | R$24.354 | R$11.897 | 3 | 3 | 1 | 1 | 27 | 18 | 595 | 380 |
| Paulo Afonso | 0 | 9 | R$166.082 | R$100.512 | 158 | 0 | R$12.786 | R$3.007 | 3 | 3 | 1 | 1 | 18 | 9 | 380 | 205 |
| Poções | 0 | 15 | R$218.593 | R$117.397 | 240 | 0 | R$32.772 | R$16.174 | 3 | 3 | 1 | 1 | 25 | 10 | 560 | 245 |
| Ribeira do Pombal | 0 | 15 | R$245.728 | R$114.394 | 215 | 0 | R$34.879 | R$13.857 | 4 | 3 | 1 | 1 | 27 | 12 | 610 | 250 |
| Santa Maria da Vitória | 1 | 7 | R$212.417 | R$172.822 | 264 | 156 | R$21.367 | R$18.430 | 3 | 3 | 1 | 1 | 27 | 21 | 590 | 480 |
| Santo Amaro | 0 | 1 | R$122.182 | R$120.983 | 0 | 0 | R$20.207 | R$19.288 | 3 | 3 | 1 | 1 | 29 | 28 | 570 | 545 |
| Santo Antônio de Jesus | 2 | 3 | R$123.410 | R$135.769 | 0 | 39 | R$20.984 | R$20.475 | 3 | 3 | 1 | 1 | 31 | 30 | 550 | 535 |
| Senhor do Bonfim | 1 | 6 | R$160.129 | R$123.630 | 126 | 29 | R$16.350 | R$13.363 | 3 | 3 | 1 | 1 | 24 | 19 | 505 | 405 |
| Teixeira de Freitas | 2 | 10 | R$144.523 | R$122.263 | 49 | 29 | R$25.021 | R$12.511 | 3 | 3 | 1 | 1 | 26 | 18 | 600 | 410 |
| Valença | 6 | 4 | R$163.985 | R$177.464 | 102 | 142 | R$25.823 | R$26.069 | 3 | 3 | 1 | 1 | 24 | 26 | 525 | 565 |
| Vitória da Conquista | 12 | 0 | R$117.301 | R$267.097 | 0 | 220 | R$16.287 | R$25.605 | 3 | 5 | 1 | 1 | 27 | 39 | 600 | 865 |
| Xique Xique | 0 | 17 | R$233.587 | R$108.833 | 322 | 0 | R$22.683 | R$9.602 | 3 | 3 | 1 | 1 | 26 | 9 | 535 | 205 |
| Agências excluídas** | 204 | 0 | R$0 | R$2.641.460 | 0 | 848 | R$0 | R$185.059 | 0 | 66 | 0 | 22 | 0 | 204 | 0 | 4.300 |
| Total Superintendência | 258 | 258 | R$4.767.815 | R$6.415.108 | 3.776 | 2.591 | R$650.253 | R$590.167 | 83 | 149 | 26 | 48 | 720 | 720 | 15.305 | 15.305 |
| * Agências excluídas: Bom Jesus da Lapa, Brumado, Cachoeira, Cipó, Esplanada, Euclides da Cunha, Ilhéus, Irecê, Itaberaba, Itamaraju, Itapetinga, Jequié, Jeremoabo, Livramento de nossa Senhora, Morro do Chapéu, Porto Seguro, Remanso, Riachão do Jacuípe, Santa Rita de Cássia, São Francisco do Conde, Seabra, Serrinha | ||||||||||||||||
#
estrategias_pnadc_sum%>%
group_by(descricao)%>%
select(-modelo)%>%
reframe(across(everything(), diff))%>%
group_by(descricao)%>%
arrange(descricao)%>%
slice(1)%>%
arrange(desc(n_agencias), custo_total)%>%
select(descricao, n_agencias, custo_total, custo_total_entrevistadores, custo_diarias, custo_combustivel)%>%
ungroup%>%
#arrange(-custo_total)%>%
gt::gt()%>%
gt::cols_label(descricao='Modelo')%>%
gt::tab_caption("Redução de custos promovido pela otimização da rede de coleta")%>%
print_gt()| Modelo | N Agencias | Custo Total | Custo Total Entrevistadores | Custo Diarias | Custo Combustivel |
|---|---|---|---|---|---|
| sem custo fixo / sem custo de treinamento | −1 | −R$115.154 | R$0 | −R$127.468 | R$9.032 |
| sem mínimo de entrevistador, remuneracao entrevistador por mês 2675, sem custo fixo | −3 | −R$699.028 | −R$706.200 | −R$50.418 | R$45.129 |
| mínimo de entrevistador=2, remuneracao entrevistador por mês 2675, sem custo fixo | −13 | −R$948.616 | −R$1.187.700 | R$153.765 | R$68.844 |
| mínimo de entrevistador=3, remuneracao entrevistador 2675 por mês, sem custo fixo | −22 | −R$1.647.293 | −R$2.118.600 | R$396.808 | R$60.086 |
Caso 4. Um novo modelo de coleta nas Agências
A seção anterior demonstrou que, pelo menos no caso da coleta da POF da Bahia, é possível atingir uma significativa redução de custos de coleta, quando contabilizamos a remuneração dos entrevistadores. Investigamos nessa seção se, ao contabilizar outras pesquisas do IBGE executadas pelas agências, em conjunto, a redução de custos ainda é observada.
A lista de pesquisas incluídas é incompleta, mas já nos possibilita
ter alguma ideia sobre, na perspectiva do modelo de otimização do
orce, a estrutura ideal da rede de coleta do IBGE. Temos,
até o momento:
- Pesquisas da Amostra Mestra (Domiciliares):
- Pesquisa Nacional por Amostra de Domicílios Contínua - PNADC
- Cadastro Nacional de Endereços para Fins Estatísticos - CNEFE
- Pesquisa de Orçamentos Familiares (POF)
- Pesquisas Municipais
- Duas visitas por ano para cada um dos municípios do Estado. (Por exemplo, Munic e alguma outra.)
## amostra mestra/pnadc
amostra_mestra <- readr::read_rds(here::here("data-raw/amostra_br_2024_01_2025_06.rds"))%>%
filter(ano_mes>=as.Date("2024-07-01"), ano_mes<=as.Date("2025-06-01"))
amostra_pnadc <- amostra_mestra%>%
distinct(uc=upa, pesquisa=paste("pnadc", substr(ano_mes,1,7)), agencia_codigo, dias_coleta=params$dias_coleta_pnadc, viagens=params$viagens_pnadc)
library(lubridate)## so months works
amostra_cnefe <- amostra_mestra%>%
filter(entrevista_numero==1)%>%
mutate(ano_mes=ano_mes-months(3))%>%
distinct(uc=upa, pesquisa=paste("cnefe", substr(ano_mes,1,7)), agencia_codigo, dias_coleta=params$dias_coleta_cnefe, viagens=params$viagens_cnefe)
## amostra pof
load(file.path(pof2024ba:::package$cache_dir, "amostra_preliminar.rda"))
amostra_pof <- amostra_preliminar%>%
distinct(uc=upa, pesquisa=paste("pof", if_else(trimestre==1, 2024, 2025), if_else(trimestre==1, 4, trimestre-1)), agencia_codigo=as.character(agencia_codigo), dias_coleta=params$dias_coleta_pof, viagens=params$viagens_pof)
## municipais
municipais <- municipios_22%>%
sf::st_drop_geometry()%>%
left_join(agencias_bdo_mun%>%select(agencia_codigo, municipio_codigo), by="municipio_codigo")%>%
mutate(uc=municipio_codigo)%>%
## com agências intramunicipais tem mais de uma agência associada a município
## vamos deixar só a primeira (em ordem numérica)
group_by(municipio_codigo)%>%
arrange(agencia_codigo)%>%
slice(1)%>%
ungroup()%>%
distinct(uc, pesquisa="municipais", agencia_codigo, viagens=params$viagens_municipios_carga, dias_coleta=params$dias_coleta_municipios_carga)
carga_br <- bind_rows(amostra_cnefe, amostra_pnadc, amostra_pof, municipais)%>%
group_by(uc, agencia_codigo, municipio_codigo=substr(uc,1,7))%>%
summarise(dias_coleta=sum(dias_coleta), viagens=sum(viagens))
#> `summarise()` has grouped output by 'uc', 'agencia_codigo'. You can override
#> using the `.groups` argument.
uf_codigo_now <- 29
ufnow <- ufs%>%filter(uf_codigo==uf_codigo_now)
carga_uf <- carga_br%>%
filter(substr(uc,1,2)==ufnow$uf_codigo)%>%
## Importante: Sem as agências de Salvador
filter(!grepl("2927408", agencia_codigo))%>%
#ungroup#%>%filter(agencia_codigo%in%c("291360600", "291480200", "292870300", "293290300", "290490200", "292740800", "292740801", "291640100"))
ungroup#%>%filter(agencia_codigo%in%unique(agencia_codigo)[1:20])
## distancias uc
distancias_ucs_all <- readRDS("/Users/eleon/gitlab/orce/data-raw/distancias_agencias_setores_osrm.rds")%>%
rename(uc=setor)%>%
bind_rows(distancias_agencias_municipios_osrm%>%rename(uc=municipio_codigo))%>%
transmute(uc, agencia_codigo, distancia_km, duracao_horas, municipio_codigo=substr(uc,1,7))%>%
left_join(agencias_municipios_diaria, by=c("agencia_codigo", "municipio_codigo"))%>%
semi_join(carga_uf, by="uc")%>%
mutate(diaria_pernoite=duracao_horas>params$horas_viagem_pernoite)
agencias_uf <- carga_uf%>%
group_by(agencia_codigo)%>%
summarise(n_ucs_jurisdicao=n(), dias_coleta_jurisdicao=sum(dias_coleta))%>%
mutate(uc_agencia_max=Inf,
dias_coleta_agencia_max=Inf, custo_fixo=0)
## sem custo fixo nem custo de treinamento
params_carga_0 <- list(ucs=carga_uf,
agencias=agencias_uf,
custo_litro_combustivel = params$custo_litro_combustivel,
custo_hora_viagem = params$custo_hora_viagem,
kml = params$kml,
valor_diaria = params$valor_diaria,
## em um ano de coleta, um entrevistador consegue
## 48 upas pnadc / 24 upas POF / 18 Municipios
dias_coleta_entrevistador_max=params$dias_coleta_entrevistador_max_carga,
diarias_entrevistador_max=Inf,
dias_treinamento = 0,
agencias_treinadas = NULL,
agencias_treinamento = NULL,
distancias_ucs=distancias_ucs_all,
## for symphony solver
#gap_limit=5,
adicional_troca_jurisdicao = params$adicional_troca_jurisdicao,
solver=params$solver,
max_time=params$max_time,
rel_tol=params$rel_tol,
resultado_completo=FALSE
)
library(tictoc)
#tic()
estrategias_carga <- bind_rows(
tibble(params_carga=list(params_carga_0),
descricao='sem custo fixo / sem custo de treinamento'),
tibble(params_carga=list(modifyList(params_carga_0,
list( remuneracao_entrevistador=12*2500)
)),
descricao='sem mínimo de entrevistador, remuneracao 2500, sem custo fixo'),
tibble(params_carga=list(modifyList(params_carga_0,
list(
agencias=agencias_uf,
remuneracao_entrevistador=12*params$remuneracao_entrevistador)
)),
descricao='sem mínimo de entrevistador, sem custo fixo'),
tibble(params_carga=list(modifyList(params_carga_0,
list(n_entrevistadores_min=2,
remuneracao_entrevistador=12*params$remuneracao_entrevistador,
max_time=params$max_time)
)),
descricao='mínimo de 2 entrevistadores, sem custo fixo'),
tibble(params_carga=list(modifyList(params_carga_0,
list(
agencias=agencias_uf%>%
mutate(
custo_fixo=10000*12),
n_entrevistadores_min=2,
remuneracao_entrevistador=12*params$remuneracao_entrevistador,
max_time=max(params$max_time, 60*60)
#max_time=
))),
descricao='mínimo de 2 entrevistadores /2 Técnicos 10000 p/ mes (custo fixo)'),
tibble(params_carga=list(modifyList(params_carga_0,
list(
distancias_ucs=params_carga_0$distancias_ucs%>%
mutate(diaria_municipio=FALSE),
agencias=agencias_uf%>%
mutate(
custo_fixo=10000*12),
n_entrevistadores_min=2,
remuneracao_entrevistador=12*params$remuneracao_entrevistador
))),
descricao='mínimo 2 entrevistadores /2 Técnicos (10000 p/ mes custo fixo), reorganizacao jurisdicao'),
tibble(params_carga=list(modifyList(params_carga_0,
list(
valor_diaria=params$valor_diaria*2,
distancias_ucs=params_carga_0$distancias_ucs,
agencias=agencias_uf%>%
mutate(
custo_fixo=10000*12),
n_entrevistadores_min=2,
remuneracao_entrevistador=12*params$remuneracao_entrevistador
))),
descricao='mínimo de 2 entrevistadores/2 Técnicos 10000 p/ mes (custo fixo)/ custo diaria 2x')
)%>%
#ungroup%>%slice(-1)%>%
mutate(resultado=purrr::map(params_carga, ~do.call(alocar_municipios, .x)))
#toc()
estrategias_carga_sum <-
estrategias_carga%>%
rowwise(descricao)%>%
reframe(
bind_rows(
resultado$resultado_agencias_otimo%>%mutate(modelo="Ótimo"),
resultado$resultado_agencias_jurisdicao%>%mutate(modelo="Jurisdição"))%>%
group_by(modelo)%>%
mutate(n_agencias=1)%>%
summarise(across(matches("custo|n_agencias"), ~sum(.x, na.rm=TRUE))))%>%
mutate(custo_total=custo_deslocamento+custo_fixo+custo_total_entrevistadores)%>%
select(descricao, modelo, n_agencias, custo_total, everything())
#report_plans(estrategias_carga$resultado[[1]])
estrategias_carga_sum%>%
group_by(descricao)%>%
arrange(descricao, modelo)%>%
select(-modelo)%>%
summarise(across(everything(), diff))%>%
arrange(desc(n_agencias), custo_total)%>%
select(descricao, n_agencias, custo_total, custo_total_entrevistadores, custo_diarias, custo_combustivel)%>%
#arrange(-custo_total)%>%
gt::gt()%>%
gt::cols_label(descricao='Modelo')%>%
gt::tab_caption("Redução de custos promovido pela otimização da rede de coleta")%>%
print_gt()| Modelo | N Agencias | Custo Total | Custo Total Entrevistadores | Custo Diarias | Custo Combustivel |
|---|---|---|---|---|---|
| sem custo fixo / sem custo de treinamento | 0 | −R$117.855 | R$0 | −R$121.605 | R$2.122 |
| sem mínimo de entrevistador, sem custo fixo | −1 | −R$594.544 | −R$642.000 | −R$23.115 | R$56.320 |
| sem mínimo de entrevistador, remuneracao 2500, sem custo fixo | −3 | −R$534.402 | −R$630.000 | −R$7.035 | R$83.414 |
| mínimo de 2 entrevistadores, sem custo fixo | −6 | −R$680.782 | −R$898.800 | R$135.005 | R$66.011 |
| mínimo de 2 entrevistadores/2 Técnicos 10000 p/ mes (custo fixo)/ custo diaria 2x | −20 | −R$2.445.552 | −R$802.500 | R$585.245 | R$135.762 |
| mínimo 2 entrevistadores /2 Técnicos (10000 p/ mes custo fixo), reorganizacao jurisdicao | −32 | −R$3.640.948 | −R$1.027.200 | R$1.026.608 | R$161.081 |
| mínimo de 2 entrevistadores /2 Técnicos 10000 p/ mes (custo fixo) | −32 | −R$3.365.024 | −R$1.027.200 | R$1.318.560 | R$149.502 |
Conclusão
A otimização da rede de coleta promovida pelo pacote
orce tem um impacto significativo na redução de custos,
principalmente pela diminuição dos custos fixos associados às agências.
A estratégia mais eficaz envolve a combinação da redução do número de
agências, a imposição de limites de UPAs por agência e a reorganização
da jurisdição, e é provavelmente vantajoso (impor o limite) para a boa
gestão da coleta.
É importante ressaltar que a otimização deve considerar não apenas os
custos, mas também outros fatores como a qualidade dos dados coletados e
a capacidade operacional das agências. O pacote orce
oferece flexibilidade para ajustar os parâmetros e restrições do modelo,
permitindo encontrar a solução que melhor se adapta às necessidades e
particularidades de cada pesquisa.
Apêndice: Detalhes técnicos do problema de otimização
Este apêndice detalha o problema de otimização que o pacote orce resolve, que é a alocação ideal de Unidades de Coleta (UCs) às agências, com o objetivo de minimizar os custos totais, incluindo custos de deslocamento e custos fixos de cada agência. O modelo de otimização é baseado no problema clássico de localização de armazéns, e é baseado em “The Warehouse Location Problem”, de Dirk Schumacher.
O Desafio
Dadas as localizações das UCs e das agências, a tarefa é decidir quais agências serão utilizadas e como as UPAs serão distribuídas entre elas. Em outras palavras, precisamos decidir simultaneamente:
- Quais agências treinar/contratar.
- Como alocar as UC a cada agência.
Começamos com um conjunto de UCs e um conjunto de agências potenciais que poderiam ser ativadas. Também temos uma função de custo que fornece o custo de viagem de uma agência para uma UC. Além disso, há um custo fixo (incluindo custos de treinamento, entre outros) associado a cada agência, caso ela seja selecionada para a coleta de dados. Agências com um pequeno número de UCs podem ser inviáveis. Agências no interior com um grande número de UCs também podem ser inviáveis. A solução deve ter pelo menos min_upas e no máximo max_upas por agência ativada. Observe que, ao permitir a coleta “semi-centralizada”, não há limite para o número de UCs nas agências listadas.
Para modelar essa situação, usamos duas variáveis de decisão:
: uma variável binária que assume o valor 1 se a UC for alocada à agência e 0 caso contrário.
: uma variável binária que assume o valor 1 se a agência for selecionada para realizar a coleta e 0 caso contrário.
$$ \begin{array}{ll@{}ll} \text{minimizar} & \displaystyle\sum\limits_{i=1}^{n}\sum\limits_{j=1}^{m} custo\_de\_viagem_{i,j} \cdot x_{i, j} + \sum\limits_{j=1}^{m} custo\_fixo_{j} \cdot y_{j}& &\\ \text{sujeito a} & \displaystyle\sum\limits_{j=1}^{m} x_{i, j} = 1 & i=1 ,\ldots, n&\\ & \displaystyle x_{i, j} \leq y_j, & i=1 ,\ldots, n & j=1 ,\ldots, m\\ & x_{i,j} \in \{0,1\} &i=1 ,\ldots, n, & j=1 ,\ldots, m \\ & y_{j} \in \{0,1\} &j=1 ,\ldots, m& \\ & \operatorname{(opcional)} \sum\limits_{i=1}^{n}{x}_{i,j} >= ( \operatorname{min\_upas} \cdot y_{j}) & j=1 ,\ldots, m& \\ & \operatorname{(opcional)} \sum\limits_{i=1}^{n}{x}_{i,j} <= \operatorname{max\_upas}_{j} & j=1 ,\ldots, m& \end{array} $$
Explicação:
- Função Objetivo: Minimizar o custo total, que é a soma dos custos de viagem para cada UC alocada a uma agência e dos custos fixos de cada agência ativada.
-
Restrições:
- Cada UC deve ser alocada a exatamente uma agência.
- Uma agência só pode receber UCs se estiver ativa.
-
Opcional: Cada agência ativada deve ter pelo menos
min_upasUCs alocadas. -
Opcional: Cada agência ativada deve ter no máximo
max_upasUCs alocadas.
Variáveis de Decisão:
-
x[i, j]: Indica se a UC
ié alocada à agênciaj(1 se sim, 0 se não). -
y[j]: Indica se a agência
jestá ativa (1 se sim, 0 se não).
Este modelo matemático representa o problema de alocação ótima e é
resolvido pelo pacote orce para encontrar a solução que
minimiza os custos totais, considerando as restrições e os custos
específicos de cada cenário.
Apêndice: Função principal: alocar_ucs
A função alocar_ucs realiza a alocação otimizada de
Unidades de Coleta (UCs) às agências, buscando minimizar os custos
totais de deslocamento e operação. O processo de otimização considera
diversas variáveis e restrições para encontrar a solução mais
eficiente.
Entradas da Função
-
Dados das UCs (
ucs):-
uc: código único da UC -
agencia_codigo: código da agência à qual a UC está atualmente alocada -
dias_coleta: número de dias de coleta na UC -
viagens: número de viagens necessárias para a coleta na UC
-
-
Dados das Agências (
agencias): (opcional, se não fornecido, assume as agências das UCs)-
agencia_codigo: código único da agência
-
-
Parâmetros de Custo:
-
custo_litro_combustivel: custo do combustível por litro -
custo_hora_viagem: custo por hora de viagem -
kml: consumo médio de combustível do veículo (km/l) -
valor_diaria: valor da diária -
custo_fixo: custo fixo mensal da agência -
dias_treinamento: número de dias/diárias para treinamento -
adicional_troca_jurisdicao: custo adicional por troca de jurisdição
-
-
Restrições de Alocação:
-
min_uc_agencia: número mínimo de UCs por agência (exceto agências treinadas) -
max_uc_agencia: número máximo de UCs por agência -
semi_centralizada: vetor com códigos de agências sem limite máximo de UCs -
agencias_treinadas: vetor com códigos de agências já treinadas (sem custo de treinamento) -
agencias_treinamento: código da(s) agência(s) de treinamento
-
-
Dados de Distância:
-
distancias_ucs: distâncias entre UCs e agências, contendo: - uc, agencia_codigo, duracao_horas, diaria_municipio, diaria_pernoite
-
distancias_agencias: distâncias entre as agências
-
-
Outras Opções:
-
resultado_completo: se TRUE, retorna informações adicionais sobre todas as combinações de UCs e agências
-
Processamento Interno
-
Pré-processamento:
- Verifica se os argumentos de entrada são válidos
- Define o número máximo de UCs por agência, se não fornecido
- Cria a alocação por jurisdição (se
agenciasnão for fornecido, assume as agências das UCs) - Seleciona a agência de treinamento mais próxima para cada agência de coleta
- Calcula os custos de treinamento com base na distância e se a agência já foi treinada
- Combina informações de UCs e agências em um formato adequado para a otimização
- Calcula os custos de transporte (combustível, tempo de viagem, diárias) para cada combinação de UC e agência
-
Modelagem da Otimização:
- Utiliza o pacote
omprpara criar um modelo de otimização - Define variáveis de decisão:
-
x[i, j]: 1 se a UCifor alocada à agênciaj, 0 caso contrário -
y[j]: 1 se a agênciajfor incluída na solução, 0 caso contrário
-
- Define a função objetivo: minimizar o custo total (deslocamento + custos fixos das agências + custos de treinamento)
- Adiciona restrições:
- Cada UC deve ser alocada a exatamente uma agência
- Se uma UC é alocada a uma agência, a agência deve estar ativa
- Restrições de número mínimo e máximo de UCs por agência (se aplicável)
- Utiliza o pacote
-
Solução da Otimização:
- Resolve o modelo usando o solver GLPK
- Extrai a solução ótima: quais UCs são alocadas a quais agências
-
Pós-processamento:
- Cria tabelas com os resultados da alocação ótima e da alocação original (por jurisdição), tanto para UCs quanto para agências
- Se
resultado_completofor TRUE, retorna também umtibblecom todas as combinações de UCs e agências e seus respectivos custos
Saídas da Função
-
resultado_ucs_otimo: alocação ótima das UCs e seus custos -
resultado_ucs_jurisdicao: alocação original das UCs e seus custos -
resultado_agencias_otimo: alocação ótima das agências, custos e número de UCs alocadas -
resultado_agencias_jurisdicao: alocação original das agências, custos e número de UCs alocadas -
ucs_agencias_todas(opcional): todas as combinações de UCs e agências e seus custos
Observações
- O cálculo de diárias já considera jurisdição, microrregiões, áreas metropolitanas e distância/necessidade de pernoite.
- A flexibilidade do pacote permite ajustar os parâmetros e restrições para atender às necessidades específicas do planejamento da coleta de dados.